本文将详细介绍如何在 GraphRAG 中使用国内大模型(如阿里百炼),并通过中文提示词优化实体关系抽取效果,最终实现知识图谱的可视化展示。
目录
一、GraphRAG 简介
GraphRAG 是微软推出的一种结合知识图谱的检索增强生成(RAG)技术。与传统 RAG 相比,GraphRAG 通过构建实体-关系图谱,能够:
- 支持多跳推理:通过图结构连接不同文档中的信息
- 实体关系分析:自动提取文本中的实体和关系
- 社区检测:将紧密相关的实体组织成社区
- 全局与局部检索:既能回答宏观问题,也能回答细节问题
二、环境准备与安装
2.1 安装 GraphRAG
首先安装 GraphRAG 核心库:
pip install graphrag注意:推荐使用 Python 3.12 版本。
2.2 修改源码以适配国内 Embedding 模型
由于阿里百炼等国内模型对 Embedding 的批处理有特殊要求,需要修改 GraphRAG 源码中的 batch_size 设置。
修改文件路径:
graphrag/index/operations/embed_text/strategies/openai.py
# conda 环境示例
D:\anaconda\envs\graphrag\Lib\site-packages\graphrag\index\operations\embed_text\strategies\openai.py修改内容(第 36 行左右):
# 原代码:
# batch_size = args.get("batch_size", 10)
# 修改为:
batch_size = 10 # 固定批次大小为 10修改原因:阿里百炼的 Embedding API 对批处理大小有限制,最大不能超过10,固定为 10 可以确保稳定调用。
2.3 准备数据集
初始化项目:
graphrag init --root hello_world创建项目目录结构:
GraphRAG/
├── hello_world/
├── prompts/ # 提示词目录
├── settings.yaml # 配置文件
└── .env # 环境变量文件示例数据下载:
本教程使用的 input/llm.txt,prompts等 示例文件已上传至 GitHub和Gitee,可以一并下载下来,后续会用到:
📥 下载地址:
将下载的文件放入 input/ 目录即可。
三、配置国内大模型
3.1 初始化项目
对于已有文件夹在项目根目录下执行,上面已经初始化了这里就不用管:
graphrag init --root . # 将空文件夹初始化为GraphRAG项目执行后会自动生成 settings.yaml、.env 和 prompts/ 目录。
3.2 配置中文提示词
GraphRAG 默认使用英文提示词,这会导致提取的实体和关系也是英文。为了适配中文环境,我已经准备了中文版的提示词文件。
中文提示词下载:
📥 下载地址:
下载后解压到 prompts/ 目录,替换原有文件。主要包括:
extract_graph.txt- 实体关系抽取提示词community_report_graph.txt- 社区报告生成提示词summarize_descriptions.txt- 描述总结提示词- 等其他提示词文件
3.3 配置大模型 API
将你的API填写在.env文件中 示例:
GRAPHRAG_API_KEY=sk-xxx⚠️ 提示:这里需要填写你的阿里百炼 API Key、Base URL 等信息,API Key来自上面的.env文件,API Base如果使用的不是阿里百炼,自行更改为OpenAI兼容请求端点。 关键配置项(参考我的
settings.yaml):
models:
default_chat_model:
encoding_model: cl100k_base
type: openai_chat # or azure_openai_chat
api_base: https://dashscope.aliyuncs.com/compatible-mode/v1
auth_type: api_key # or azure_managed_identity
api_key: ${GRAPHRAG_API_KEY} # set this in the generated .env file
model : qwen-flash
model_supports_json: true # recommended if this is available for your model.
concurrent_requests: 25 # max number of simultaneous LLM requests allowed
async_mode: threaded # or asyncio
retry_strategy: native
max_retries: 3 # set to -1 for dynamic retry logic (most optimal setting based on server response)
default_embedding_model:
encoding_model: cl100k_base
type: openai_embedding # or azure_openai_embedding
api_base: https://dashscope.aliyuncs.com/compatible-mode/v1
auth_type: api_key # or azure_managed_identity
api_key: ${GRAPHRAG_API_KEY}
model: text-embedding-v4
model_supports_json: true # recommended if this is available for your model.
concurrent_requests: 5 # max number of simultaneous LLM requests allowed
async_mode: threaded # or asyncio
retry_strategy: native
max_retries: 3 # set to -1 for dynamic retry logic (most optimal setting based on server response)
batch_size: 10 # 这里指定batch为10也没有用,所以就采取了上面的直接修改源码的方式
dimensions: 1024
encoding_format: "float"
vector_store:
default_vector_store:
type: lancedb
db_uri: output\lancedb
container_name: default
overwrite: True
embed_text:
model_id: default_embedding_model
vector_store_id: default_vector_store
### Input settings ###
input:
type: file # or blob
file_type: text # or csv
base_dir: "input"
file_encoding: utf-8
file_pattern: ".*\\.txt$$"
chunks:
size: 1200
overlap: 100
group_by_columns: [id]
### Output settings ###
## If blob storage is specified in the following four sections,
## connection_string and container_name must be provided
cache:
type: file # [file, blob, cosmosdb]
base_dir: "cache"
reporting:
type: file # [file, blob, cosmosdb]
base_dir: "logs"
output:
type: file # [file, blob, cosmosdb]
base_dir: "output"
### Workflow settings ###
extract_graph:
model_id: default_chat_model
prompt: "prompts/extract_graph.txt"
entity_types: [organization,person,geo,event]
max_gleanings: 1
summarize_descriptions:
model_id: default_chat_model
prompt: "prompts/summarize_descriptions.txt"
max_length: 500
extract_graph_nlp:
text_analyzer:
extractor_type: regex_english # [regex_english, syntactic_parser, cfg]
extract_claims:
enabled: false
model_id: default_chat_model
prompt: "prompts/extract_claims.txt"
description: "Any claims or facts that could be relevant to information discovery."
max_gleanings: 1
community_reports:
model_id: default_chat_model
graph_prompt: "prompts/community_report_graph.txt"
text_prompt: "prompts/community_report_text.txt"
max_length: 2000
max_input_length: 8000
cluster_graph:
max_cluster_size: 10
embed_graph:
enabled: false # if true, will generate node2vec embeddings for nodes
umap:
enabled: false # if true, will generate UMAP embeddings for nodes (embed_graph must also be enabled)
snapshots:
graphml: false
embeddings: false
### Query settings ###
## The prompt locations are required here, but each search method has a number of optional knobs that can be tuned.
## See the config docs: https://microsoft.github.io/graphrag/config/yaml/#query
local_search:
chat_model_id: default_chat_model
embedding_model_id: default_embedding_model
prompt: "prompts/local_search_system_prompt.txt"
global_search:
chat_model_id: default_chat_model
map_prompt: "prompts/global_search_map_system_prompt.txt"
reduce_prompt: "prompts/global_search_reduce_system_prompt.txt"
knowledge_prompt: "prompts/global_search_knowledge_system_prompt.txt"
drift_search:
chat_model_id: default_chat_model
embedding_model_id: default_embedding_model
prompt: "prompts/drift_search_system_prompt.txt"
reduce_prompt: "prompts/drift_search_reduce_prompt.txt"
basic_search:
chat_model_id: default_chat_model
embedding_model_id: default_embedding_model
prompt: "prompts/basic_search_system_prompt.txt"
四、索引构建实战
4.1 执行索引构建
确保配置完成后,执行索引构建命令:
graphrag index --root .4.2 索引成功的标志
日志检查:
索引过程中会在 logs/ 目录生成日志文件。查看日志内容,确认没有报错信息:
# linux系统查看最新日志,windows直接打开文件查看即可
cat logs/indexing-engine.log成功标志:
- ✅ 日志中显示各个步骤完成(如
extract_graph,community_reporting等) - ✅ 没有 API 调用失败或超时错误
- ✅
output/目录下生成了以下文件
输出结果检查:
索引成功后,output/ 目录应包含以下 parquet 文件:
output/
├── lancedb/
│ ├── default-community-full_content.lance/
│ ├── default-entity-description.lance/
│ └── default-text_unit-text.lance/
├── communities.parquet
├── community_reports.parquet
├── context.json
├── documents.parquet
├── entities.parquet
├── relationships.parquet
├── stats.json
└── text_units.parquet五、问答查询演示
5.1 设计查询问题
基于我们使用的 llm.txt 文件(关于 LangChain Agents 的文档),我们设计一个能够体现 GraphRAG 优势的问题:
问题:
LangChain中的智能体(Agents)是如何实现工具调用和推理的?请详细说明ReAct循环的工作流程。为什么选择这个问题?
- 涉及多个实体:
Agents、Tools、ReAct循环、模型等 - 需要跨文档推理:答案分散在文档的不同部分
- 体现关系抽取能力:实体之间的调用关系、工作流程
5.2 执行查询
局部检索(Local Search):
graphrag query --root . --method local --query "LangChain中的智能体(Agents)是如何实现工具调用和推理的?请详细说明ReAct循环的工作流程。"回答结果:
LangChain中的智能体(Agents)通过结合语言模型(LLM)与外部工具(Tools),实现对复杂任务的推理与行动。其核心机制依赖于“推理+行动”(ReAct)模式,该模式在智能体执行任务时交替进行内部思考(推理)与外部工具 调用(行动),从而逐步达成目标。这一过程由`create_agent`函数创建的智能体运行时驱动,该运行时基于LangGraph构建图结构,使智能体能够以状态化的方式管理多步骤任务流程 [Data: Entities (1, 3, 56, 38); Relationships (30, 20, 31, [Data: Sources (2); Relationships (27)]。随后,系统执行该工具调用,返回搜索结果,例如列出五款无线耳机,其中WH-1000XM5排名最高 [Data: Sources (2); Relationships (29)]。智能体接着再次推理,决定需要检查该产品的库存,于是调用`check_inventory`工具,传入产品ID“WH-1000XM5” [Data: Sources (2); Relationships (28)]。工具返回库存为10单位后,智能体完成最终推理,生成包含产品型号和库存状态的回复,如“我找到了最受欢迎的无线耳机(型号WH-1000XM5),目前有10个库存” [Data: Sources (2); Relationships (29)]。整个过程体现了ReAct模式的核心——将推理与行动在每一步交替进行,利用工具反馈不断修正决策路径。
ReAct循环在LangChain中通过`create_agent`函数实现,并被明确集成在智能体的执行流程中。该模式依赖于语言模型的推理能力与工具调用的可执行性,使得 智能体不仅能理解任务,还能主动规划并执行多步操作 [Data: Entities (31, 23); Relationships (30, 20)]。此外,智能体在执行过程中可通过中间件(Middleware)扩展功能,例如使用`@wrap_tool_call`装饰器实现工具调用的错误处理,或使用`@dynamic_prompt`实现系统提示的动态生成,从而增强系统的鲁棒性与适应性 [Data: Entities (56, 37, 28, 38); Sources (1, 2)]。同时,LangChain支持流式输出(STREAMING)机制,允许在智能体逐步执行过程中实时返回token,提升用户体验 [Data: Entities (40); Sources (3)]。
综上,LangChain中的智能体通过ReAct循环实现了从任务理解到工具调用再到最终决策的完整链路,其机制融合了推理、状态管理、工具集成与可扩展的中间件 系统,为构建具备自主决策能力的复杂AI应用提供了坚实基础。全局检索(Global Search):
graphrag query --root . --method global --query "LangChain中的智能体(Agents)是如何实现工具调用和推理的?请详细说明ReAct循环的工作流程。"回答结果:
### LangChain智能体的推理与工具调用机制
LangChain中的智能体(Agents)通过结合**推理(Reasoning)**与**工具调用(Action)**的交替执行,实现复杂的多步骤任务处理。其核心机制是**ReAct循环**,该循环由智能体内部的推理过程(Thought)与对外部工具的调用(Action)构成,形成一个“推理+行动”的闭环。智能体首先基于当前上下文生成思考(Thought),判断是否需要调用工具;若需要,便生成具体工具调用指令(Action);工具执行后返回结果(Observation),智能体再根据观察结果进行新一轮推理,判断任务是否完成或是否需要进一步操作。该流程支持多步骤任务的自主执行,是构建复杂智能体系统的技术基础 [Data: Reports (1, 3, 2, 7, 9, +more]。
### ReAct循环的工作流程详解
ReAct循环的执行流程包括以下六个关键步骤:
1. **接收用户输入(INPUT)**:智能体启动任务,接收用户的初始请求或指令。
2. **生成内部思考(Thought)**:智能体基于输入和当前上下文进行推理,例如判断“我需要查询天气信息”。
3. **决定并生成工具调用(Action)**:根据思考结果,智能体决定调用相应的外部工具,如`Get_Weather`或`Search`,并生成标准的调用指令。
4. **执行工具并返回观察结果(Observation)**:工具通过标准接口执行,返回实际数据,如“当前天气为晴,温度25℃”。
5. **基于观察进行新一轮推理**:智能体分析工具返回的结果,判断任务是否完成,或是否需要进一步操作。
6. **重复循环直至目标达成**:上述过程持续进行,直到任务被完全解决。整个流程由模型驱动,工具调用通过标准化接口完成,确保了任务执行的可追踪性与可控制性 [Data: Reports (1, 3, 2, 7, 9, +more]。
### 工具调用与错误处理机制
智能体的工具调用依赖于LangChain的统一工具集成机制,支持预设工具(如`Search`、`Get_Weather`)和自定义工具(如`tool1`、`tool2`)。这些工具通过 统一接口被调用,实现信息获取与操作,使智能体能够突破语言模型的局限,执行实际任务。工具执行后的反馈以`Observation`形式返回,作为下一步推理的输入,构成闭环反馈链 [Data: Reports (1, 3, 2, 9, 4, +more]。
为增强系统的鲁棒性,LangChain通过`WRAP_TOOL_CALL`中间件装饰器封装工具调用,用于处理执行过程中可能出现的异常,如超时、权限拒绝或服务中断。当工具调用失败时,该装饰器会捕获错误并返回结构化的错误信息,避免任务中断,从而提升智能体系统的容错性与可靠性 [Data: Reports (0, 5, 9, 1, 2, +more]。
### 状态管理与中间件架构
智能体的运行依赖于Runtime环境,该环境整合了**不可变的Context**与**可变的State**,以支持动态模型选择和上下文感知决策。`CustomState`类与`STATE_SCHEMA`共同定义自定义状态的结构模式,使状态管理具有可配置性。在多轮交互中,State持续更新并传递,确保上下文连贯性。例如,系统可根据用户对某工 具的高频使用记录(来自State)自动推荐该工具,体现了状态在长期行为建模中的作用 [Data: Reports (0, 8)]。
中间件架构在ReAct循环中发挥关键作用。`BEFORE_MODEL`中间件在模型调用前处理状态,如注入上下文或进行权限验证;`AFTER_MODEL`中间件在响应生成后进 行内容过滤或格式化,以确保输出的安全性与一致性。这些中间件与`CustomState`协同工作,支持高度定制化的推理行为 [Data: Reports (0, 5)]。
### 动态模型选择与性能优化
智能体系统支持动态模型选择,由`wrap_model_call`中间件实现。该装饰器在模型调用前动态修改所使用的模型,系统可根据对话复杂度或上下文信息(如用户身份)选择轻量级模型(如GPT-4O-MINI)或高性能模型(如GPT-4O、GPT-5)。这使得智能体在处理简单请求时使用低开销模型,而在复杂任务中切换至更强大 模型,从而在性能与成本之间取得平衡,提升整体效率和可扩展性 [Data: Reports (5)]。
### 推理引擎与系统依赖
智能体的推理能力由核心模型(如GPT-4O-MINI、GPT-4O、GPT-5)提供,这些模型作为推理引擎,负责生成思考与决策。在实际系统中,模型通过`ChatOpenAI` 类与OpenAI服务集成,构成完整的从输入到输出的链路。这一依赖链表明智能体系统高度依赖外部模型服务,任何模型中断或变更都将影响整体行为 [Data: Reports (1, 3, 7, 2, +more]。
综上所述,LangChain智能体通过ReAct循环实现推理与工具调用的协同,结合状态管理、中间件架构与动态模型选择,构建了一个高可靠性、可扩展且上下文感 知的自动化系统。该系统不仅能够完成复杂任务,还能在错误发生时保持稳定运行,是实现高级人工智能应用的核心技术框架。5.3 查询结果分析
局部检索 vs 全局检索:
GraphRAG 的优势体现:
- ✅ 能够关联文档不同部分的信息
- ✅ 通过图结构理解实体间的关系
- ✅ 支持多跳推理(如:Agents → Tools → Model → ReAct)
六、输出文件详解
GraphRAG 在索引过程中会生成多个 parquet 文件,每个文件都有特定的作用。以下内容参考自 超越传统 RAG:GraphRAG 全流程解析与实战指南。
6.1 text_units.parquet - 文本单元
字段说明:
作用:文本单元是索引的基础,后续的实体和关系都是从这些文本单元中提取的。
6.2 entities.parquet - 实体表
字段说明:
作用:实体是知识图谱的节点,代表文本中的关键概念或对象。
6.3 relationships.parquet - 关系表
字段说明:
作用:关系是知识图谱的边,描述实体之间的联系。
6.4 communities.parquet - 社区表
字段说明:
作用:社区是通过图聚类算法(Leiden)检测出的紧密相关的实体集合,有助于理解知识的组织结构。
6.5 community_reports.parquet - 社区报告
字段说明:
作用:社区报告是对每个社区的结构化总结,在全局检索时会用到。
6.6 查看 parquet 文件
使用 pandas 可以轻松查看这些文件:
import pandas as pd
# 查看实体表
df_entities = pd.read_parquet('output/entities.parquet')
print(df_entities.head())
# 查看关系表
df_relationships = pd.read_parquet('output/relationships.parquet')
print(df_relationships.head())七、可视化分析
我已经准备了两个 Jupyter Notebook 文件(从上面的GitHub链接中下载),用于直观展示 GraphRAG 的输出结果。
7.2 analysis1.ipynb - 图结构可视化
功能:
- 读取
text_units.parquet、entities.parquet、relationships.parquet - 可视化展示文本单元中的实体关系图
- 展示社区内部的图结构
- 显示支撑证据(文本单元)
使用方法:
- 打开
analysis1.ipynb - 确保已安装依赖:
pip install pandas networkx matplotlib- 运行所有单元格
示例输出:
Notebook 会生成知识图谱的可视化图表,展示:
- 实体节点(蓝色圆圈)
- 关系边(带箭头的线)
- 关系描述(边上的标签)
7.2 analysis2.ipynb - 社区报告可视化
功能:
- 读取
community_reports.parquet文件 - 按重要性(rank)排序展示社区
- 可视化展示社区的标题、摘要、详细报告和关键发现
使用方法:
- 打开
analysis2.ipynb - 确保已安装依赖:
pip install pandas jupyter ipython- 运行所有单元格
示例输出:
Notebook 会展示类似以下的可视化内容:
🏷️ 社区报告 (Community ID: 2)
**标题:** LangChain Agents 核心机制
📝 核心摘要
该社区主要涉及 LangChain 中的智能体系统...
📖 详细深度报告
[完整报告内容]
🔍 关键发现点 (Findings)
1. Agents 通过 ReAct 模式实现推理与行动循环
2. 工具调用支持并行和顺序执行
...八、Neo4j 图数据库可视化
为了更专业地展示知识图谱,我们可以将 GraphRAG 的输出导入到 Neo4j 图数据库中。
8.1 部署 Neo4j
我已经准备了 Docker Compose 配置文件,可以一键部署 Neo4j。
配置文件,在项目根目录创建docker-compose.yaml文件,将下面内容复制进去:
version: '3.8'
services:
neo4j:
image: neo4j:latest
container_name: neo4j_graphrag
restart: unless-stopped
ports:
- "7474:7474" # Neo4j Browser (Web UI)
- "7687:7687" # Bolt 协议端口
environment:
# 设置初始用户名和密码
# 格式:NEO4J_AUTH=用户名/密码
- NEO4J_AUTH=neo4j/graphrag123
# 内存配置(根据你的机器配置调整)
- NEO4J_server_memory_heap_initial__size=512m
- NEO4J_server_memory_heap_max__size=2G
- NEO4J_server_memory_pagecache_size=512m
# 启用 APOC 插件(高级图算法和工具)
- NEO4J_PLUGINS=["apoc"]
# 允许从文件导入数据
- NEO4J_dbms_security_procedures_unrestricted=apoc.*
volumes:
# 数据持久化:将容器内数据映射到本地
- ./neo4j_data:/data
- ./neo4j_logs:/logs
- ./neo4j_import:/var/lib/neo4j/import
- ./neo4j_plugins:/plugins
healthcheck:
test: [ "CMD-SHELL", "wget --no-verbose --tries=1 --spider http://localhost:7474 || exit 1" ]
interval: 10s
timeout: 5s
retries: 5
start_period: 30s
# 使用说明:
# 1. 启动服务:docker-compose up -d
# 2. 查看日志:docker-compose logs -f
# 3. 停止服务:docker-compose down
# 4. 停止并删除数据:docker-compose down -v
# 5. 访问 Neo4j Browser:http://localhost:7474
# 用户名:neo4j
# 密码:graphrag123部署步骤:
-
确保已安装 Docker 和 Docker Compose
-
确保还在项目的根目录:
-
启动 Neo4j:
docker-compose up -d -
查看启动状态:
docker-compose logs -f -
访问 Neo4j Browser:
- 打开浏览器访问:http://localhost:7474
- 默认用户名:
neo4j - 默认密码:
graphrag123
8.2 导入数据到 Neo4j
使用准备好的 Python 脚本将 GraphRAG 输出导入 Neo4j。
在项目根目录创建export_neo4j.py,将下面内容复制进去:
import pandas as pd
from neo4j import GraphDatabase
import time
# neo4j 环境配置
NEO4J_URI = "bolt://127.0.0.1:7687"
NEO4J_USERNAME = "neo4j"
NEO4J_PASSWORD = "graphrag123"
NEO4J_DATABASE = "neo4j" # 使用默认数据库
# 将 DataFrame
def batched_import(statement, df, batch_size=1000):
total = len(df)
start_s = time.time()
for start in range(0,total, batch_size):
batch = df.iloc[start: min(start + batch_size,total)]
result = driver.execute_query("UNWIND $rows AS value " + statement,
rows=batch.to_dict('records'),
database_=NEO4J_DATABASE)
print(result.summary.counters)
print(f'{total} rows in {time.time() - start_s} s.')
return total
driver = GraphDatabase.driver(NEO4J_URI, auth=(NEO4J_USERNAME, NEO4J_PASSWORD))
# parquet 文件存储目录
GRAPHRAG_FOLDER = "./output"
text_units = pd.read_parquet(GRAPHRAG_FOLDER + "/text_units.parquet")
entities = pd.read_parquet(GRAPHRAG_FOLDER + "/entities.parquet")
relationships = pd.read_parquet(GRAPHRAG_FOLDER + "/relationships.parquet")
communities = pd.read_parquet(GRAPHRAG_FOLDER + "/communities.parquet")
community_reports = pd.read_parquet(GRAPHRAG_FOLDER + "/community_reports.parquet")
# 导入 text_units
statement = """
MERGE (c:__Chunk__ {id:value.id})
SET c += value {.text, .n_tokens}
WITH c, value
UNWIND value.document_ids AS document
MATCH (d:__Document__ {id:document})
MERGE (c)-[:PART_OF]->(d)
"""
batched_import(statement, text_units)
# 导入 entities
entity_statement = """
MERGE (e:__Entity__ {id:value.id})
SET e += value {.human_readable_id, .description, name:replace(value.title,'"','')}
WITH e, value
CALL apoc.create.addLabels(e, case when coalesce(value.type,"") = "" then [] else [apoc.text.upperCamelCase(replace(value.type,'"',''))] end) yield node
UNWIND value.text_unit_ids AS text_unit
MATCH (c:__Chunk__ {id:text_unit})
MERGE (c)-[:HAS_ENTITY]->(e)
"""
batched_import(entity_statement, entities)
# 导入 relationships
relationships_statement = """
MATCH (source:__Entity__ {name:replace(value.source,'"','')})
MATCH (target:__Entity__ {name:replace(value.target,'"','')})
// not necessary to merge on id as there is only one relationship per pair
MERGE (source)-[rel:RELATED {id: value.id}]->(target)
SET rel += value {.weight, .human_readable_id, .description, .text_unit_ids}
RETURN count(*) as createdRels
"""
batched_import(relationships_statement, relationships)
# 导入 communities
communities_statement = """
MERGE (c:__Community__ {id:value.id})
SET c += value {.level, .title, .community}
/*
UNWIND value.text_unit_ids as text_unit_id
MATCH (t:__Chunk__ {id:text_unit_id})
MERGE (c)-[:HAS_CHUNK]->(t)
WITH distinct c, value
*/
WITH *
UNWIND value.relationship_ids as rel_id
MATCH (start:__Entity__)-[:RELATED {id:rel_id}]->(end:__Entity__)
MERGE (start)-[:IN_COMMUNITY]->(c)
MERGE (end)-[:IN_COMMUNITY]->(c)
RETURN count(distinct c) as createdCommunities
"""
batched_import(communities_statement, communities)
# 导入 community_reports
community_reports_statement = """
MERGE (c:__Community__ {community:value.community})
SET c += value {.level, .title, .rank, .rank_explanation, .full_content, .summary}
WITH c, value
UNWIND range(0, size(value.findings)-1) AS finding_idx
WITH c, value, finding_idx, value.findings[finding_idx] as finding
MERGE (c)-[:HAS_FINDING]->(f:Finding {id:finding_idx})
SET f += finding
"""
batched_import(community_reports_statement, community_reports)使用步骤:
-
安装 Neo4j Python 驱动:
pip install neo4j pandas -
修改脚本配置(如果需要):
# export_neo4j.py 中的配置 NEO4J_URI = "bolt://127.0.0.1:7687" NEO4J_USERNAME = "neo4j" NEO4J_PASSWORD = "graphrag123" GRAPHRAG_FOLDER = "./output" -
在项目根目录执行导入脚本:
python export_neo4j.py -
等待导入完成: 脚本会依次导入:
- ✅ 文本单元(Text Units)
- ✅ 实体(Entities)
- ✅ 关系(Relationships)
- ✅ 社区(Communities)
- ✅ 社区报告(Community Reports)
8.3 在 Neo4j 中查询可视化
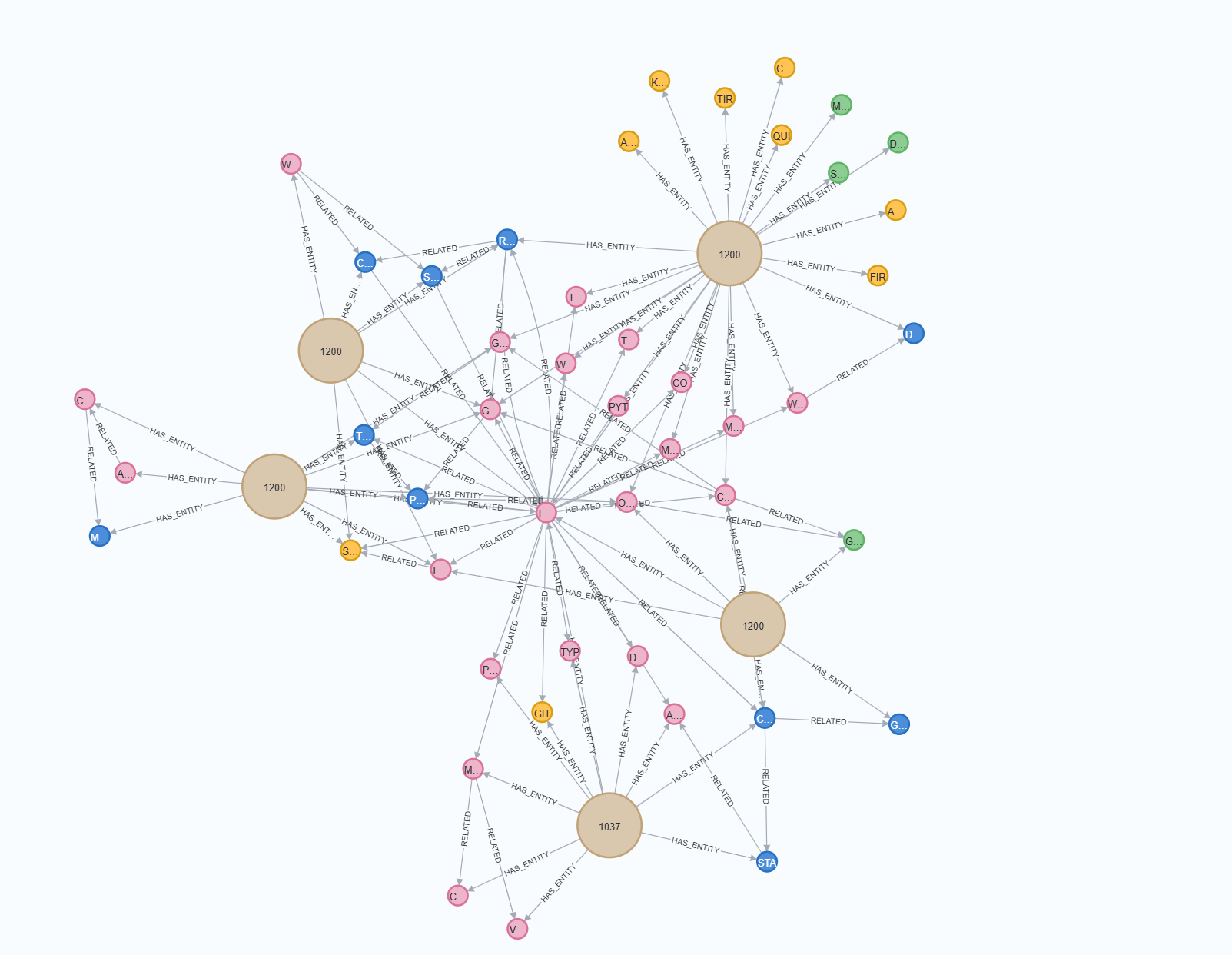 导入成功后,可以在 Neo4j Browser 中执行 Cypher 查询语句进行可视化。
导入成功后,可以在 Neo4j Browser 中执行 Cypher 查询语句进行可视化。
示例查询 1:查看所有实体和关系
MATCH (a)-[r]->(b)
RETURN a, r, b
LIMIT 100示例查询 2:查看特定实体的关联关系
MATCH (source:__Entity__)-[rel:RELATED]-(target:__Entity__)
WHERE source.name = "OPENAI" OR target.name = "GPT-5"
RETURN source, rel, target示例查询 3:查看某个社区的内部结构
MATCH (c:__Community__ {community: 2})
MATCH (e:__Entity__)-[r:IN_COMMUNITY]->(c)
RETURN c, e, r示例查询 4:查看社区间的关系
MATCH (e1:__Entity__)-[:IN_COMMUNITY]->(c1:__Community__)
MATCH (e2:__Entity__)-[:IN_COMMUNITY]->(c2:__Community__)
MATCH (e1)-[r:RELATED]->(e2)
WHERE c1.community <> c2.community
RETURN c1, e1, r, e2, c2
LIMIT 50可视化效果:
Neo4j Browser 会以交互式图形展示查询结果,你可以:
- 🔍 缩放和拖动节点
- 📊 查看节点和关系的详细属性
- 🎨 根据实体类型自动着色(建议调整不同类型节点的颜色和大小,可以帮助你更加直观的分析)
- 🔗 探索节点的关联关系
九、总结
通过本教程,我们完成了以下内容:
✅ 完成的工作
-
安装配置:
- 安装 GraphRAG 并修改源码以适配国内模型
- 配置阿里百炼等国内大模型 API
-
中文优化:
- 使用中文提示词确保实体和关系的可读性
- 验证中文环境下的索引构建
-
索引构建:
- 成功对示例文档进行索引
- 生成实体、关系、社区等结构化数据
-
问答演示:
- 体验局部检索和全局检索
- 验证 GraphRAG 的多跳推理能力
-
可视化分析:
- 使用 Jupyter Notebook 分析输出结果
- 通过 Neo4j 实现专业的图数据库可视化
💡 核心优势
相比传统 RAG,GraphRAG 的优势在于:
- 结构化知识:将文本转化为实体-关系图谱
- 多跳推理:通过图结构连接分散的信息
- 社区检测:自动发现知识的组织结构
- 双模式检索:局部检索快速响应,全局检索深度分析
🚀 后续优化方向
- 提示词优化:根据具体领域调整实体类型和关系定义
- 参数调优:调整 chunk_size、overlap 等参数提升效果
- 混合检索:结合局部和全局检索获得最佳结果
- 增量更新:研究如何高效更新知识图谱
📚 参考资源
- GraphRAG 官方文档
- 超越传统 RAG:GraphRAG 全流程解析与实战指南
- 本教程配套资源(GitHub):
附录
常见问题
Q1:索引构建时遇到 API 调用失败怎么办?
A:检查以下几点:
- 确认 API Key 和 Base URL 配置正确
- 检查网络连接是否正常
- 查看是否有速率限制(rate limit)
- 查看
logs/目录下的错误日志
Q2:为什么提取的实体和关系全是英文?
A:确保已经替换了中文提示词文件(prompts/ 目录)。
Q3:Neo4j 无法启动怎么办?
A:检查:
- Docker 是否正在运行
- 端口 7474 和 7687 是否被占用
- 查看 Docker 日志:
docker-compose logs
Q4:查询结果不准确怎么办?
A:可以尝试:
- 提高文档的质量,从根源上保证输入质量最有效
- 调整 chunk_size 和 overlap 参数
- 优化提示词内容
- 使用更强大的大模型
性能优化建议
- 并发控制:调整
concurrent_requests参数平衡速度和稳定性 - 批处理大小:根据模型限制调整
batch_size,可以使用支持更大batch的模型提供商 - 缓存利用:充分利用
cache/目录避免重复调用 - 资源监控:监控 API 调用次数和 Token 消耗